



負荷分散型クラスタ
クラスタシステムとは
簡単にいえば、複数のサーバ(ノードという)をあたかも一台のサーバのように見せかけるための技術です。サーバ一台で処理行えば、十分に業務は可能だという場合も多いでしょう。しかし、昨今においてサーバ一台ですべての処理を行う形態では、多くの問題を抱えることが多くなってきました。例えば、運用中のサーバが何らかの障害によって停止した場合を想定してみましょう。顧客情報などを取り扱ったり、予約情報などの更新中に停止すると業務そのものが停滞し大きな混乱を招きます。サーバ一台ではトラブルが発生した場合に、対処することができません。
次に、Webサーバでサービスを行っている場合を考えてみましょう。ユーザの訪問回数が多くなった場合、サーバが一台ではアクセスの過負荷が原因で均等なサービスを提供できなくなる可能性があります。オンラインショッピングサイトでは、サービスの遅延が致命的な損害を被ることにもなりかねません。
これらの事態を想定して事前に備えておく方法として「クラスタシステム」を導入します。
クラスタシステムは、次のような種類に分類することができます。
- HA(HighAvailability)クラスタ
- フェイルオーバー型クラスタ
- 負荷分散型クラスタ
- HPC(HighPerformanceComputing)クラスタ
システムの異常による停止時間を最小限にするには「HAクラスタ」を利用します。サーバを複数台使って冗長化し、システムの可用性(availability)を向上させるクラスタシステムです。「HPCクラスタ」は、主に構造計算やレンダリングでの膨大な計算が必要な場合に利用します。複数台のサーバに計算等を振分けて処理を実行させます。ここでは、「HAクラスタ」を中心に紹介します。
HA (HighAvailability) クラスタシステム
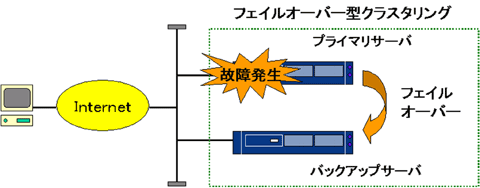
フェイルオーバー型クラスタ
障害が発生した場合でも業務の運用を継続させるためには、フェイルオーバー型クラスタを利用します。フェイルオーバー型のクラスタは、メインで動作するサーバと、待機しているサーバとでお互いに共通のアドレスを仮想的に持ちます。その上で「heartbeat信号」を利用し、異常がないかを確認します。メインのサーバがダウンすると、この信号が途絶えるので、メインのサーバに障害が発生していると判断し、処理を引き継ぎます。導入する際の注意点は、メインのサーバと待機しているサーバの間での同期をどうとるかが重要です。
参考:データの同期をとるには
フェイルオーバー型クラスタの例
負荷分散型クラスタ
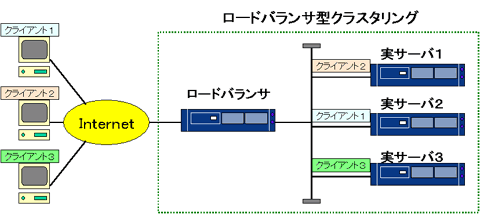
アクセスによる過負荷を回避するためには、複数台のサーバを用意して負荷を分散する技術(ロードバランサ)を使った、負荷分散型クラスタを利用します。
負荷分散型クラスタは、「ロードバランサ(仮想サーバ)」と実際に処理を行う「実サーバ」から構成されます。
ロードバランサは実サーバへ処理を割り振る場合にパケットを利用し、そのパケットヘッダやデータを参照しています。通常、IPアドレスとポート番号を元にして振分け先を決定し、ひとつのコネクション内のパケットは全て単一の実サーバに振分けられるようにすることで、外部から接続したクライアントと実サーバ間のコネクションの一貫性を維持することが可能になっています。処理の要となるロードバランサが複数の実サーバから、処理を一任するサーバを選択する際には様々な方法があります(後述)。
負荷分散型クラスタの例
オープンソースを利用してクラスタシステムを構築する優位性
クラスタシステムを構築するには、ハードウェアで実装する場合、ソフトウェアで実装する場合、これらを併用で実装する場合があります。商用製品はベンダーによって多種多様な仕様を持っており、必要なサービスがある製品を導入するのが一般的でしょう。 しかし、この場合は利用しないサービスも付加されることが多く、必要のない経済的コストをかけたり、必要のないサービスがトラブルの原因となることもあります。
オープンソースを利用する場合は「良質なシステムを最小のコスト」で構築することが可能です。
オープンソースが良質のシステムを実現する例として、ユーザの要求に最もフィットしたカスタマイズが可能である点でしょう。商用製品では、実装している仕様に限界があった場合、カスタマイズが出来ない場合が多く見受けられます。これは製品開発元での仕様を容易に変更できない事が要因となっています。それに対しオープンソースでは、ソースコードを改変し再配布を可能にしているので、自由にカスタマイズすることができます。また最小のコストという点でも、オープンソースはライセンスコストが発生しないので商用製品と比べると安価に構築することが可能です。
経済的なコストを抑え、長期的にみた運用の安定性を考えるならば、オープンソースでのシステムの構築が有効です。
「UltraMonkey」で実現する 負荷分散型クラスタソリューション
オープンソース・ソフトウェアで負荷分散を実現する技術として「LVS(Linux Virtual Server)」があります。ハードウェアとソフトウェアを併用して、クラスタシステムを提供する場合が多い中で、ソフトウェアのみで提供される技術です。
「LVS」 はあくまでも負荷分散を実装するためのシステムです。より信頼性のある負荷分散クラスタシステムの構築を考える場合は、フェイルオーバーの機能を組み込む必要があります。
「Ldirectord」、「heartbeat」の技術を併用するで組み込むことが可能です。これらをトータルで考えた負荷分散ソリューションが「UltraMonkey」です。
「LVS」により複数台の実サーバを用いることで、ロードバランサクラスタの構築が可能ですが、「LVS」だけでは複数台を運用する(多重化)事により、信頼性の向上をはかることは難しくなっています。
「UltraMonkey」で信頼性を向上させるために
「LVS」により構築されたロードバランサの構成マシンが故障した場合、故障の部位によりクライアントからはサービスが間欠的に停止、あるいは完全に停止したように見えます。
「Ultra Monkey」では、このような現象について次のような対応をしています。
負荷分散クラスタが故障した場合におこる現象
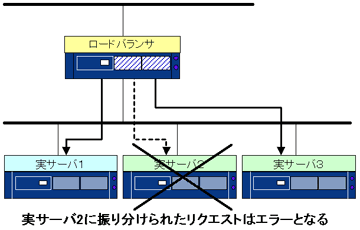
実サーバの故障
複数ある実サーバのうちの一台が故障した場合、図に示すようにクライアントからは、サーバが間欠的に故障しているように見えます。これは、ロードバランサが故障した実サーバと、健全な実サーバを区別せずに、クライアントからの要求を振り分けてしまうためです。ロードバランサが実サーバの故障を検出し、さらに故障した実サーバに、クライアントからの要求を振り分けないようにすることができれば、実サーバの故障を隠蔽することができます。
「Ultra Monkey」では、「Ldirectord」を使って、実サーバの故障検出や切り離しを行っています。
実サーバの故障
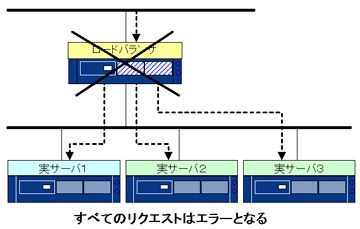
ロードバランサの故障
ロードバランサが故障した場合、図に示すようにクライアントからはサーバが完全に故障したように見えます。
ロードバランサの故障
ロードバランサの故障を隠蔽するために、「Ultra Monkey」ではロードバランサをまず2台用意し、片方を運用サーバ、他方を運用サーバが落ちた際の予備のサーバ(待機サーバ)として動作させる構成です。さらに運用サーバと、待機サーバで「heartbeat」を使って、相互にサーバの状態を監視し、運用サーバのダウンが検出された際に、待機サーバが運用サーバのIPアドレスを引き継いでサービスを継続できるようにしています。
ロードバランサの構成
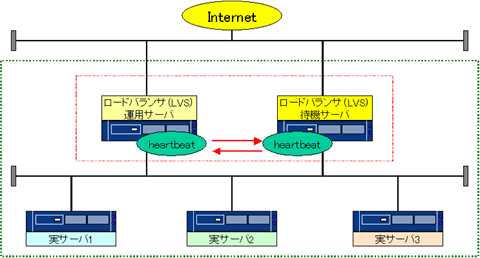
ロードバランサを二重化する場合の限界について
heartbeatを用いてロードバランサを二重化している場合においても、完全にロードバラ ンサの故障が隠蔽できるわけではありません。実サーバとコネクションを張っているクライアントがいる状態で、ロードバランサがダウンした場合、クライアントと実サーバの対応関係までは引き継ぎできません(※1)。結果として、コネクションは通信途中で切れてしまうことになります。
よって、ロードバランサを二重化した場合、故障が発生した時にコネクションを張っていたクライアントには、故障が見えてしまいます。よって、完全にロードバランサの故障を隠蔽しなければならないようなケースでは、現状の 「LVS」を使用することはできません。
「LVS」を用いたロードバランサの性能測定
測定項目
500B、4KB、33KB、500KB、5MBのファイルを受け取る際の、
(1)1秒あたりのリクエスト処理数
(2)ロードバランサでのデータ転送速度
の2点を測定しました。
ネットワーク構成
フェイルオーバー型クラスタの例
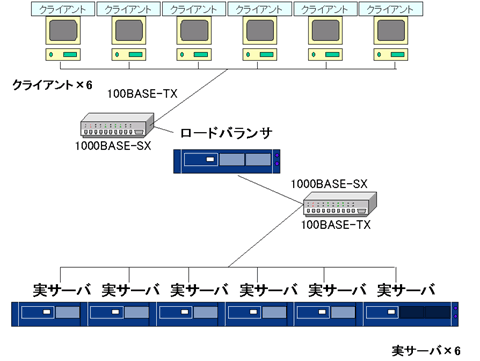
コンピュータ構成
ロードバランサ
| CPU | Intel PentiumⅠⅠⅠ/933MHz |
|---|---|
| Memory | 1GB |
| NIC | NetGear GA620(ドライバ:acenic) |
| Linux Kernel | 2.4.18 |
| LVS | ipvs-1.0.3 |
実サーバ
| CPU | Intel PentiumⅠⅠⅠ/933MHz |
|---|---|
| Memory | 512MB |
| NIC | Intel EtherExpress Pro/100B |
| Linux Kernel | 2.4.18 |
| Web Server | Apache 2.0.35 |
性能評価用クライアント
| CPU | Intel PentiumⅠⅠⅠ/866MHz |
|---|---|
| Memory | 512MB |
| NIC | Intel EtherExpress Pro/100B |
| Linux Kernel | 2.4.18 |
| 性能評価プログラム | WebStone 2.5b3 |
スイッチ
| 機種 | CentreCOM 9006SX/SC |
|---|
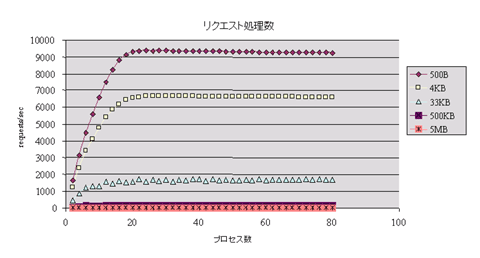
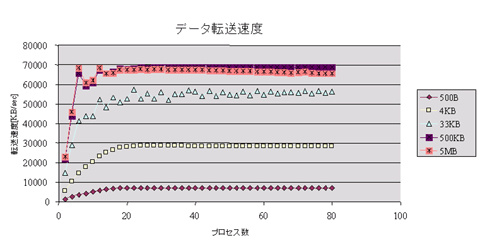
測定結果
考察
以上の結果から、転送するファイルサイズが大きい場合では、転送速度が66MB/sec程度で飽和しています。実サーバ1台あたりの転送速度は約90Mbit/secとなり、100BASE-TXのイーサネットの帯域をほぼ使い切ると考えられます。このことより、転送速度の飽和の原因は 「LVS」がボトルネックになっているわけではないと推測できます。
またそれに対して、転送するファイルサイズが小さい場合では、イーサネットの帯域を使い切れていないことを示しています。これは、Webサーバへのコネクションの開設処理や、ハードウェアの性能など複数の要素が絡んできますが、データ転送が行われていない時間が相対的に大きくなるためと考えられます。
以上ように、「LVS」を使用したロードバランサの性能は、各種サービスに有効に利用可能であると考えられます。
今後の取り組み
NFS は古くからあるプロトコルなだけに、機能・性能で不足しがちな面が存在しました。次のバージョンのNFSv4 では、既存の実装の再利用は考慮せずに、根本から実装の設計を改訂しています(以下の資料参照)。
今後は、NFSの高可用性について重点におき、性能向上が図れるよう開発に取り組みたいと考えています。
*NFSの開発の成果はLinuxコミュニティへフィードバックされております。
- ※1 「LVS」にはクライアントと実サーバの対応関係を、待機ノードの 「LVS」に転送するための初歩的なコードは存在しますが、まだ異常系の処理が不完全で実運用に使用できるレベルではありません。