



タイマーハードウェアの抽象化
Linuxでは、タイマーハードウェアを 2種類に分類し、それぞれ抽象化してカーネルに機能を提供しています。
- Clocksource
– 時間の読み取り - Clockevents
– 指定時刻に割り込み
Linux の動作するシステムでは、計時、割り込みともに複数のハードウェアを持つことが普通ですが、ストレージなどとは異なり、いずれも同じ働きをします。そこで、各ハードウェアに対応するデバイスドライバが、精度やアクセス速度などに基づいて rating を定め、システムが rating の高いものを選択して利用します。
Clocksource
Clocksource は計時に使われ、xtime 更新時や、カーネル内 API である ktime_get_*()、システムコール gettimeofday() 実行時などに参照されます。
sysfs の以下のファイルに、現在利用可能な選択肢が現れます。
/sys/devices/system/clocksource/clocksource0/available_clocksource
【実行例】
$ cat /sys/devices/system/clocksource/clocksource0/available_clocksource
tsc hpet acpi_pm
それぞれ前回出てきた以下の計時ハードウェアを駆動するドライバの名称です (カッコ内は rating。RHEL 6の場合)。
- tsc: TSC (300、旧型など 0 の場合もアリ)
- hpet: HPET (250)
- acpi_pm: ACPI 電源管理タイマー (200、旧型など一部で 120)
- kvm-clock: KVM PV Clock (400)
- xen: Xen PV Clock (400)
- pit: i8254 PIT (110、マルチプロセッサマシンや HPET がある場合は選択できない)
現在 IA マシンで主流の CPU では、tsc の rating が最も高くなり、これが用いられるのが普通です。KVM または Xen のゲストでは、それぞれの PV Clock の rating が最高になります。
必要に応じて起動オプションまたは sysfs への書き込みで他の clocksource を強制することもできます。
起動オプションは、
clocksource=jiffies/tsc/hpet/acpi_pm/…
選択肢 jiffies は、計時ハードウェアを参照するのではなく、jiffies を使って計時をするもので、起動オプションでのみ選択できます。ちなみに、Red Hat Enterprise Linux では 4 まで常に jiffies を使った実装でした。後述の dyntick 利用時には使えません (派手に時計が狂います)。また jiffies はティック速度 (HZ) 単位であり、たとえば x86_64 アーキテクチャの RHEL では HZ=1000 なので 1ミリ秒単位、同じく Ubuntu では HZ=250 なので 4ミリ秒単位でしか時刻が得られないことになります。
sysfs の以下のファイルへの書き込みにより、その場で変更できます。
/sys/devices/system/clocksource/clocksource0/current_clocksource
同じファイルで現在の clocksource を参照することもできます。
【実行例】
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
kvm-clock
$ sudo echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
Clockevents
Clockevents は時間により割り込みをかけるデバイスを抽象化したものです。broadcast デバイスと per-CPU デバイスとが定義されています。手で切り替えることはできませんが、RHEL 7 以降では現在のデバイスは sysfs の以下のファイルで参照できます。
/sys/devices/system/clockevents/broadcast/current_device
/sys/devices/system/clockevents/clockeventX/current_device
前者が現在の broadcast デバイスを、後者が CPU X の per-CPU デバイスを参照します。
【実行例】
$ cat /sys/devices/system/clockevents/broadcast/current_device
hpet
$ cat /sys/devices/system/clockevents/clockevent0/current_device
lapic
通常は per-CPU デバイスが利用され、per-CPU デバイスが省電力モード (深い Cステート) に入って止まってしまっている場合に broadcast デバイスが使われます。これらの使い分けは自動的に行なわれます。
IA サーバにおける clockevents デバイスは、以下の通りです (カッコ内は rating。RHEL 6 の場合)。
- lapic: Local APICタイマー (100、ARATがある場合 150)
- hpet: HPET (50、FSB割り込みがある場合 110)
- pit: i8254 PIT (0)
したがって、以下のように選択されます。
- ARAT のある最近のマシンでは (ただし broadcast デバイスが利用される機会はない)
– per-CPU デバイス: lapic
– broadcast デバイス: hpet
- ARAT がなく、HPET が FSB 割り込み (MSI) をサポートした n 個のタイマーを持つ場合
– per-CPU デバイス: 最初の n 個は hpet、残りは lapic
– broadcast デバイス: hpet
- ARAT がなく、HPET が FSB 割り込みを持たない場合
– per-CPU デバイス: lapic
– broadcast デバイス: hpet
そのココロは、精度やアクセス時/割り込み時のオーバーヘッドなどからは LAPICタイマーが望ましいのだけれど、止まると broadcast device に切り替える必要があって面倒なので、止まらない (ARATがある) なら LAPICタイマーを利用し、HPET が LAPICタイマー並みに低いオーバーヘッドで利用できる (すなわち、FSB 割り込みが使える) ならば HPET を使う、という感じだと思います。
なお、RHEL 5/6 には、/sys/devices/system/clockevents がありませんが、/proc/timer_list の後半に実際に利用されているデバイスが出てきます。timer_list にはタイマー関連のさまざまな情報が含まれていますが、たいへん見にくいのでソースコード (kernel/time/timer_list.c) と対照しながら見る必要があると思います。
Clockevents は、カーネル内のいろんな人が好き勝手に使うと当然破綻しますので、カーネルの中でも比較的低レイヤにあるタイマー関連のサブシステムのみが利用します。具体的には、tick か high-resolution timer (hrtimer) のいずれかです。
hrtimer が low-resモードならば、clockevents を周期的 (periodic) モードで tick が利用します。periodicモードでは、指定された時間毎に周期的に割り込みがかかります。hrtimer のコールバックは、この tick の割り込みの延長で呼ばれます。
periodicモードがないデバイスでは、ワンショットモードで割り込みのたびに設定し直します。
hrtimer が high-resモードであれば、ワンショットモードで hrtimer が利用します。この場合、tick は low-resモードのときとは逆に hrtimer のコールバックとして呼ばれます。
Dyntick (NOHZ、tickless)
Tick の話に戻ります。Tick は 1/HZ秒ごとに呼ばれ、さまざまな定時処理をするわけですが (第1回参照)、システムのアクティビティが低いときにも同じように呼び出され、あまりうれしくありません。
CPU が、長時間と予測されるアイドルに入ると、省電力モードに移行するわけですが、最近の CPU では、コア毎などに CPU のキャッシュを停止したり、コア自体の電力供給をカットしたりすることができるようになっており、省電力モードには入るのも出るのも高いコストがかかります。そこで、一定の条件のもと、tick を次に timer wheel が expire する時刻まで遅延させるようにしたのが、dyntick と呼ばれる仕組みです。
一定の条件とは、
- アイドルループ内 (すなわち当該 CPU で実行すべきプロセスがない)
- Pending になっている softirq がない
- Timer wheel に expire するタイマーがこの先 1 tick 以上ない
第1回で説明した tick で行なわれている処理のうち、
- jiffies の更新 / xtime の更新
→ 誰か 1つの CPU が行なえばよい処理。他のアイドルではない CPU に任せる。
→ 全 CPU がアイドルであれば、参照する人がいないため、いずれかの CPU がアイドルじゃなくなったときにまとめて更新すればよい。clocksource を参照し、経過時間を正確に知ることができる。
→ clocksource=jiffies とした場合、tick に依存する jiffies の更新を、jiffies 自身を参照して行なう、ということになり、計時が破綻します。Dyntick と clocksource=jiffies が共存できないのはこのためです。
- load average の計算 (10tick に 1度)
→ 誰か 1つの CPU が行なえばよい処理。他のアイドルではない CPU に任せる。
→ 全 CPU がアイドルであれば、参照する人がいないため、いずれかの CPU がアイドルじゃなくなったときにまとめて更新すればよい。
- timer wheel コールバックの実行 (softirq 利用)
→ 次のタイマーが expire する時刻に起きられるよう clockevents を設定する。
- hrtimer コールバックの実行
→ hrtimer/clockevents がよきに計らってくれる (次の tick より前にスケジュールされているコールバックがあれば、tick より前にタイマー割り込みが入る)。
- CPU 利用率統計の更新 (sys%, user%, …、per-cpu、per-task)
タスクスケジューラ呼び出し (プリエンプト)
→ アイドル時に必要な処理ではない。
まとめ
第1回で最初に紹介した「カーネル内での時刻/時間の利用」のそれぞれは、これまでに説明した以下のような処理が対応します。
- 時刻の管理 (gettimeofday/settimeofday)、起動からの時間 (uptime) の計測
→ wall clock、xtime
→ tickにより更新 - NTPデーモン (ntpd) による時刻調整 (adjtimex)
→ wall clock、xtime を調整 - プロセスの同期処理 (sleep/nanosleep や、select/poll などでのタイムアウト処理)
→ hrtimer を利用 - プロセスのプリエンプト (タイムスライスを使い切ったプロセスから CPU を奪う)
→ hrtimer や tick を利用 - ネットワークのタイムアウト処理、再送タイマなど
→ timer wheel を利用 - デバイスのタイムアウト処理
→ timer wheel を利用 - システムの CPU 利用統計 (%user/%nice/%system%iowait/%idle)
→ tickで更新 - プロセスの CPU 利用統計 (プロセスの優先度やタイムスライスの計算などに使われる
→ tickで更新
→ スケジューラークロックを参照 - その他各種帯域制御など
→ hrtimer を利用、など
これらの関係を図にしてみますと、こんな感じかと思います。
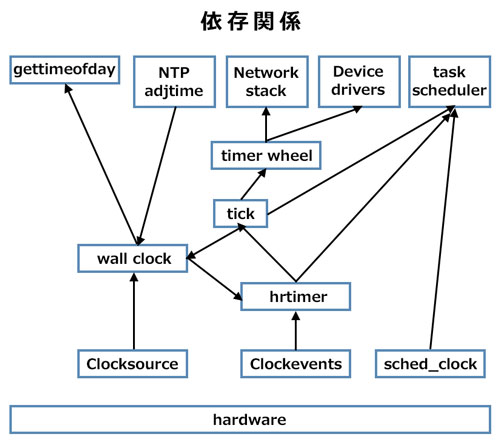
4回にわたり「カーネルにおけるタイマー事情」について解説してきました。Linux ソースコード読解の助けになれば幸いです。