




概要
11月18日から21日にかけてサンディエゴで開催された KubeCon + CloudNativeCon North America 2019 に参加したのでその様子を報告する。
会場はダウンタウンにある San Diego Convention Center で、床面積は昨年のシアトルの会場よりちょっと広い程度のようだが、実質ワンフロアで横に広く (端から端まで 500m くらいある)、セッション間の移動が大変であった。
サンディエゴは 7年前の OpenStack Summit で 10月に行ったときの温暖な印象があったが、今回は到着した日は暑かったものの後半は雨で寒くなるといった感じであまり天候には恵まれなかった。
街中には電動キックボードがそこいらに置いてあって、ホテルから会場まで歩いて 10分ほどだったので使ってみようと思ったが、アプリで unlock しようとしたら US の運転免許証を要求されて使えなくて残念であった。
https://www.cncf.io/announcement/2019/11/19/cloud-native-computing-foundation-continues-tremendous-growth-surpassing-500-members/ によれば 12,000 人の参加者数だったそうだ。初日のスポンサーブースは結構な混雑だったが、それを除けば、キーノート会場も含め会場のキャパシティ的にはまだ余裕がある感じであった。
全体的な雰囲気としては、もう Kubernetes を使っていることは前提で、Day 2 Operation という言い方をしている人もいたが、その上で運用をどう改善していくかという話が主流だったような気がした。
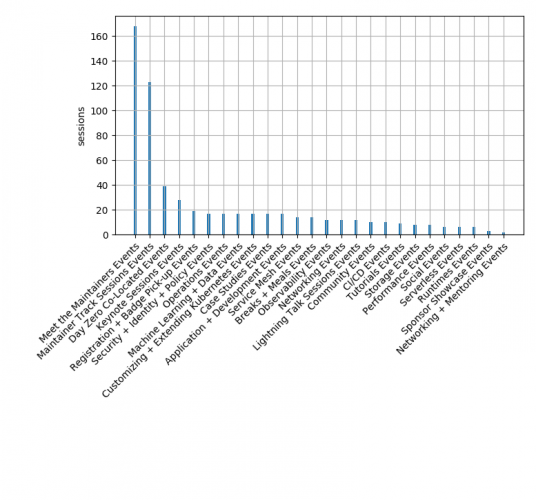
図は https://kccncna19.sched.org/ のトラックごとのセッション数をグラフにしたものである。
Meet the maintainers というのは、スポンサーブースの脇に小さなブースがあって開発者に直接質問できるコーナーのことである。Maintainer Track Sessions は名前の通りで開発の動向を話すセッションである。Kubernetes の SIG の他にも CNCF のプロジェクト数が沢山あるので数がすごいことになっている。Intro と Deep Dive に分けて 2回やるのが通例であったが、今回は Intro + DeepDive という表記にて 1回で済ませているプロジェクトが多くみられた。
分野毎のトラックは、グラフからは幅広く分散しているという見方ができる。
その中での最多セッションは Security + Identity + Policy で、セキュリティ関連の話題はメジャーなトピックの一つではあったが、そればかりが目立つという感じではなかった。セキュリティ以外にも,データベースやストレージや (Open) テレメトリといった、運用していく上で課題となるものが比較的ホットな話題だという印象を受けたが、著者の主観も入っていると思われる。
スポンサーブース
スポンサーブースは相変わらず派手であったが、会場の都合か小スポンサーの小さなブース (話をきくと結構面白いことをやっていたりもする) がまとめて通路を挟んだ別の場所になっていて、そっちはあまり人通りも多くなく少し寂しい雰囲気だった。
ブースが多いと見てもらうのも簡単ではなく、抽選券を配って (数万円程度の) 高額賞品で釣るというのが伝統的なやり方だが、今回見掛けたものとして、手品師を使って人目を引くということをやっているブースがあった。
また、スポンサーブースにモニタ画面を置いて自社製品のプレゼンを見せてその場にいる人の中から抽選で賞品を渡すというのもよくみたが、 IBM では結構いい賞品をだしていた。
また、Microsoft のブースでは GitHub action のチュートリアルを受けると Raspberry PI がもらえるというのをやっていた。 (GitHub は買収されて Microsoft の一部になっている)
セッションに行けなかったので Edge の話を聞きに Futurewei にいったら代わりに KubeVirt みたいなものを作っていると説明を受けた。他に Mirantis も作っているそうなので、KubeVirt のような Kubernetes で VM を管理するものが少なくとも 3種類実装されているということである。

Google Cloud のブースは大きかったもののがらんとしていて、確かにいまさら宣伝する必要はないのかもしれないが逆に目立っていた。
Replicated (https://www.replicated.com/) のブースでは、OSS の Kubernetes 便利ツールをいろいろ宣伝してて,どうやって収益あげてるのと聞いたらそれらとは別のライセンス管理ソフトが収益源だとのことであった。便利ツールは宣伝用というか知名度のためといった感じで、そういうビジネスモデルもあるのだなと思った。
各セッションの内容
以下では、聴講したセッションの中で機械学習トラックとメンテナトラックのものの内容を紹介する。
ほぼ全てのプレゼン資料は https://kccncna19.sched.com/ からアクセスできる。
Improving Performance of Deep Learning Workloads with Volcano
Baidu の機械学習ジョブを Kubernetes 上で動かすために、Volcano という名前のバッチスケジューラを作りましたという話である。MPI をサポートしたとか、タスクのトポロジーを 考慮することで通信レイテンシを下げて性能を改善したといっていた。
最後に 例題のトレーニングジョブ を動かして性能のグラフで Volcano による改善を示していた。
会場からユーザー数の質問があったが, Baidu でもまだ内部でテストしてる段階だとのことである。
公式サイトは https://volcano.sh/ である。
Networking Optimizations for Multi-Node Deep Learning on Kubernetes
 画像をクリックすると大きな画像が表示されます
画像をクリックすると大きな画像が表示されます本題と関係ないが,このセッションの部屋では https://wordly.ai の音声認識のテストをしていて、話者の説明がこのようにリアルタイムで文字に書き起こされていた。変なところもあるが RDMA とか専門用語もちゃんと認識されててよくできてると思った。
マルチノードでディープニューラルネットの学習をやる話である。
ノード間の通信は RDMA であるが GPUDirect という技術と組み合わせることでホストメモリを経由せずに直接 GPU 間でデータ転送できるようになる。
前半で SR-IOV プラグインとか Multus とかの Kubernetes で使うための説明をしていたようであるが、遅れて行ったので直接は聞いていない。
NVIDIA の人が、RoCE (Remote Direct Memory Access (RDMA) protocol over Converged Ethernet) ではパケットロスのないネットワークを用意しなくてはいけなくて、そのための PFC とか ECN の設定の話をしていた。
また,各ノードの NIC をまとめて ToR につなぐのではなく,それぞれ別のスイッチにつないで帯域を確保しないといけないといった説明をしていた。
最後に GPU 数と性能のグラフを示していて、RDMAを使うことで 32 GPU くらいまではほぼリニアによくスケールしていた (batch=256 なら、SGD のバッチサイズが大きいほうが通信のレイテンシが隠蔽できるということだと思われる)。
最後に、飛行機が飛ぶ原理は浮力とか関係なくて金をつっこむと飛ぶんだと指導教官に教わった、ディープラーニングでも一緒だと不思議な冗談を言っていた。
Bare Metal でも一緒なのと質問されている。
あまり話すことがなかったみたいで 3時前に終了した。会場は人が少なめだった。
Introducing KFServing
KFServing というのは,学習済みモデルをサーブする model serving の一種だが、Istio と KNative の上に作ってあって serverless であるのが特徴である。Bloomberg で使ってますよと紹介していた.
Advanced Model Inferencing Leveraging KNative, Istio and Kubeflow serving
機械学習は、学習そのもののコードよりも周りのインフラのコード量がずっと多いというしばしば見る図がでてきた。
Kubeflow の話から始めていたので、昨日の “Introducing KFServing” セッションと同じ話を繰り返すのかと思っていたら、 SeldonIO/alibi の話になった。
SeldonIO/alibi は、機械学習モデルに説明を与えることを目的としたプロジェクトで、いくつかのアルゴリズムが実装されているようである。GDPR 規制に適合するためにデータ処理で使われているロジックの説明ができなければいけないということのようである。
また、トレーニングデータに小さなノイズを加えて違う推論結果がでる例などを示して、alibi-detect プロジェクトの紹介もしていた。
聴衆の数は “Introducing KFServing” も本セッションも多かった。
kubeadm deep-dive
最終日の 3時過ぎなので消化試合感があるが割と聴衆は多い。kubeadm は SIG cluster lifecycle が担当であるが、図を示して kubeadm と他のもの (etcd とか cluster add-on) の守備範囲の関係を示していた。
SIG cluster lifecycle は SCL と略するらしい。
1.16 で kustomize support が入って api server 等の static pod manifest をカスタマイズできるようになって timeout 値の変更とかが簡単になったよと言っていた。
kubeadm はクラウド事業者で実運用に使われてる(battle tested)と言っていた。また、長期的な課題として declarative にクラスタの状態を操作したい (https://github.com/kubernetes/kubeadm/issues/1698) といったものを挙げていた。
必要な機能があったら言ってくれ (your opinion DOES MATTER) と言っていた。
早めにプレゼンが終了し、質問を受けていた。certification rotation について、どうにかならないのかといった質問などが出ていた。
Deep dive into the latest kubernetes scheduler features
まずスケジューラの現状について以下のような説明があった。
- scheduler の filter function の説明
- unfeasible node を除いて score function で順位を決める
- plugin 複数箇所に足せる (Scheduling Framework による最近の新機能)
- ComponentConfig で plugin を無効にしたり順番を変えたりできる (同上)
Scheduling Framework について 1.19 までの Roadmap を示してるが順調に複雑化していってる感じがある。
他に Pod Topology Spreading 機能が alpha として入ったとか、最近 GA になった機能の紹介があった。
質疑応答では、リソースが足りなくなると scheduler のとこまできてタイムアウトしつづけるようになるが、それはどうにかならないのか、という質問があった。他にも質問が続いており、実際困ってる人がそれなりにいるということのようである。
Introduction to virtual kubelet
virtual kubelet というのは Kubernetes でないものをそうであるように kubernetes master に見せかけるもので、去年 CNCF project になった。
セッションでは virtual kubelet を淡々と説明した後 Netflix での事例の話になった。
Titus というコンテナマネージャを Kubernetes の出てくる前から使っていて、ZooKeeper とか Mesos を使って作ってあるそうである。
Titus executor と kubelet はいろいろ違いがあるという表を出して事情を説明していた。
また、Titus の API を使う内部のツールが沢山あって、いきなり Kubernetes に移行することは現実的でないようである。
そこで Titus virtual kubelet というものを作ったそうである。virtual kubelet では pod spec の形式を特に要求しない (unopinionated) ので、mesos containerinfo を base64 encode して埋めてある。ここで Kubernetes の declarative API を Titus の imperative API に変換しているそうである。これを使って Titus から Kubernetes に今年の6月に移行させたと言っていた。
難しかった点として、controller-less k8s のドキュメントがないとか、formal な pod state machine がないといったことを挙げていた。Mesos は追放したが Titus の他のコンポーネントは残っているようだ。最終的にどうしたいのかはいまいちよく分からなかった。
質疑セクションでは、他に virtual kubelet の example はないのとかといったものがあった。
Intro to Longhorn
Rancher のやっている分散ブロックストレージプロジェクトである。聴衆は 50人程だった。ロゴは Rancher (製品) とはまたちがう感じの角の絵である。最近 CNCF sandbox プロジェクトになった。
2014年からこのプロジェクトをやっていて、いまのは第三世代目の実装だそうである。
Rancher の GUI をつかって longhorn を起動するデモをしていた。起動したら longhorn の dashboard も出てきた。
longhorn は Kubernetes 上で動作して Kubernetes にストレージを提供するものであるが、作りとしては node のディスクを hostpath でもってきて longhorn 側で冗長化しているということのようである。
longhorn の PV をつかって WordPress を起動したり、longhorn volume のバックアップつくって restore したりのデモをしていた。
細かい実装の話もあって、ストレージメタデータは CRD で持っているそうである。性能に関する質問では、公式な数字はないけど Ceph よりは速そうという回答があった。
他にもいろいろ質問されており、みんなストレージは悩みの種でいいソリューションを探しているのかという感想を持った。
writemany とか readmany のボリュームは作れないのかと質問があったが、そんなに需要あるのかなと不思議に思った。(ブロックストレージなので答えは当然 No である。)
設計を見る限りシンプルに手堅く作ってあるという印象である。コミュニティの盛り上がりによっては有力な選択肢になってくるのではないかと思った。
Intro to the Kubernetes Working Group for Multi-tenancy
人はそこそこいる。マルチテナントは 2年前に初参加した Austin での Kubecon では人気のトピックだったが、淡々と進んでいるようである。
話しているのは VMware product line manager の人で、SIG では co-chair だそうである。オンラインミーティングの日時や、録画して YouTube にのせてあるといった基本情報をまず説明していた。
SIG にはいくつかのプロジェクトがあるそうで、順番に説明していた.
- hierarchical namespace controller
現在開発中で、名前の通り namespace を階層化するもので、階層化することで親 namespace で有効な RBAC ロールは自動的に子 namespace でも有効になるというふうに役に立つそうである。 - virtual clusters
Alibaba の人が Project lead をやっている。hard multi-tenancy を実現するためのもので、master はテナント毎に独立のものを用意する。worker ノードは共用だが、Kata Containers や gVisor を使ってリソース分離するというものである。開発中だそうである。 - tenant controller v2
テナントをリソースとして管理して、namespace (テナント毎に複数ある) が正しいポリシーで設定されるようにするコントローラである。アイデア出しの段階のようである。 - multi-tenancy benchmarks
Project lead は KubeCon には来ていなかった。ベンチマークではマルチテナントのレベルが3つ定義されている。 benchmark というより、必要な機能があるか確認するための test suite みたいな感じのもののようである。
現状でハードマルチテナントをやろうとすると Virtual clusters のようなアプローチは妥当なところかとも思うが、それでも結構ごちゃごちゃしていて大変そうだなと思った。
次回予告
2019年12月18日: KubeCon レポート 第2回を公開しました!
続きはこちら: KubeCon + CloudNativeCon North America 2019 (第2回)
次回は、今回紹介できなかった以下の内容などについて、また、KubeCon 本体の前日に行われた CNCF security day について書く予定です。お楽しみに…
- Keynote の目を引いた内容
- ipvlan で速いネットワークを構築した話
- NFV/telco 関連の性能チューニング